In 1992, IBM began shipping 3.5-inch hard disk drives that could actually predict their own failure – an industry first. These drives were equipped with Predictive Failure Analysis (PFA), an IBM-developed technology that periodically measures selected drive attributes – things like head-to-disk flying height – and sends a warning message when a predefined threshold is exceeded. Industry acceptance of PFA technology eventually led to SMART (Self-Monitoring, Analysis and Reporting Technology) becoming the industry-standard reliability prediction indicator for both IDE/ATA and SCSI hard disk drives.
There are two kinds of hard disk drive failures: unpredictable and predictable. Unpredictable failures happen quickly, without advance warning. These failures can be caused by static electricity, handling damage, or thermal-related solder problems, and there is nothing that can be done to predict or avoid them. In fact, 60% of drive failures are mechanical, often resulting from the gradual degradation of the drive’s performance. The key vital areas include:
- Heads/head assembly: crack on head, broken head, head contamination, head resonance, bad connection to electronics module, handling damage
- Motors/bearings: motor failure, worn bearing, excessive run out, no spin, handling damage
- Electronic module: circuit/chip failure, bad connection to drive or bus, handling damage
- Media: scratch, defect, retries, bad servo, ECC corrections, handling damage.
These have been well explored over the years and have led to disk drive designers being able to not only develop more reliable products, but to also apply their knowledge to the prediction of device failures. Through research and monitoring of vital functions, performance thresholds which correlate to imminent failure have be determined, and it is these types of failure that SMART attempts to predict.
Just as hard disk drive architecture varies from one manufacturer to another, so SMART-capable drives use a variety of different techniques to monitor data availability. For example, a SMART drive might monitor the fly height of the head above the magnetic media. If the head starts to fly too high or too low, there’s a good chance the drive could fail. Other drives may monitor additional or different conditions, such as ECC circuitry on the hard drive card or soft error rates. When impending failure is suspected the drives sends an alert through the operating system to an application that displays a warning message.
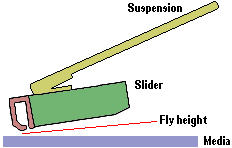
A head crash is one of the most catastrophic types of hard disk failure and – since the height at which a head flies above the surface of the media has decreased steadily over the years as one of the means to increase areal recording densities, and thereby disk storage capacities – it might reasonably be expected to be an increasingly likely form of failure. Fortunately, this is not the case, since flying height has always been one of the most critical parameters for disk drive reliability and as this has steadily decreased, so the techniques used to predict head crashes have become progressively more sophisticated. Not only are heads flying too low are in danger of crashing, but if the recording head flies higher than intended, even for a short period of time, the magnetic field available may be insufficient to reliably write to the media. This is referred to as a high fly write. External shock, vibration, media defect or contamination may cause this. Soft errors caused by this phenomenon are recoverable, but hard errors are not.
The fly height is controlled by the suspension attached to the slider containing the magnetic recording head and the airbearing of the slider. This aerodynamic system controls the variation in fly height as the slider is positioned over the surface of the media. Traversing the head between the inner and outer radius of the disk causes a two-to-one change in velocity. Prior to current technology in airbearing designs, this change in velocity would have created a two-to-one change in nominal fly height. However, with current day airbearing designs, this variation can be reduced to a fraction of the nominal value and fly heights – the distance between the read/write elements and the magnetic surface – are typically of the order of a few millionths of an inch and as low as 1.2 micro-inches. There are several conditions – for example, altitude, temperature, and contamination – that can create disturbances between the airbearing and the disk surface and potentially change the fly height.
Thermal monitoring is a more recently introduced aspect of SMART, designed to alert the host to potential damage from the drive operating at too high a temperature. In a hard drive, both electronic and mechanical components – such as actuator bearings, spindle motor and voice coil motor – can be affected by excessive temperatures. Possible causes include a clogged cooling fan, a failed room air conditioner or a cooling system that is simply overextended by too many drives or other components. Many SMART implementations use a thermal sensor to detect the environmental conditions that affect drive reliability – including ambient temperature, rate of cooling airflow, voltage and vibration – and issue a user warning when the temperature exceeds a pre-defined threshold – typically in the range 60-65°C).
The table below identifies a number of other failure conditions, their typical symptoms and causes and the various factors whose monitoring can enable impending failure to be predicted:
| Type of Failure | Symptom/Cause | Predictor |
|---|---|---|
| Excessive bad sectors | Growing defect list, media defects, handling damage | Number of defects, growth rate |
| Excessive run-out | Noisy bearings, motor, handling damage | Run-out, bias force diagnostics |
| Excessive soft errors | Crack/broken head, contamination | High retries, ECC involves |
| Motor failure, bearings | Drive not ready, no platter spin, handling damage | Spin-up retries, spin-up time |
| Drive not responding, no connect | Bad electronics module | None, typically catastrophic |
| Bad servo positioning | High servo errors, handling damage | Seek errors, calibration retries |
| Head failure, resonance | High soft errors, servo retries, handling damage | Read error rate, servo error rate |
In its brief history, SMART technology has progressed through three distinct iterations. In its original incarnation SMART provided failure prediction by monitoring certain online hard drive activities. A subsequent version improved failure prediction by adding an automatic off-line read scan to monitor additional operations. The latest SMART technology not only monitors hard drive activities but adds failure prevention by attempting to detect and repair sector errors. Also, whilst earlier versions of the technology only monitored hard drive activity for data that was retrieved by the operating system, this latest SMART tests all data and all sectors of a drive by using off-line data collection to confirm the drive’s health during periods of inactivity.
Up until the late 1990s, the implementation of RAID had been almost exclusively in the server domain. By then, however, processor speeds had reached the point where the hard disk was often the bottleneck that prevented a system running at its full potential. Aided and abetted by the availability of motherboards that included a RAID controller – by 2000 the deployment of RAID’s striping technique had emerged as a viable solution to this problem on high-end desktop systems.
- Hard disk (hard drive) construction
- Hard Disk (hard drive) Operation
- Hard disk (hard drive) format – the tracks and sectors of the hard disk
- File systems (FAT, FAT8, FAT16, FAT32 and NTFS) explained
- Hard Disk (Hard Drive) Performance – transfer rates, latency and seek times
- Hard Disk AV Capability
- Hard Disk Capacity
- Hard Disk Capacity Barriers
- Hard Disk MR Technology
- Hard Disk GMR Technology
- Hard Disk Pixie Dust
- Hard Disk Longitudinal Recording
- Hard Disk Perpendicular Recording
- RAID – Redundant Arrays of Inexpensive Disks
- Hard Disk SMART Drives
- Hard Disk MicroDrives
- Hard Disk OAW Technology
- Hard Disk PLEDM
- Hard Disk Millipede
- Guide to Western Digital’s GreenPower hard drive technology
- Solid state hard drive (SSD) technology guide